NEWS内容
- 二级分类:
- 不限 AI写作 AI绘图 AI视频 AI办公 AI设计 AI对话聊天 AI编程 AI搜索 AI音频 AI翻译 AI法律助手 AI内容检测 AI提示词 AI大模型 AI模型测评 AI学习 学习AI AI开发框架
- 已选择:
- AI工具-AI模型测评 清空

H2O EvalGPT
H2O EvalGPT 是 H2O.ai 提供的一个开放工具,专门用于评估和比较大型语言模型(LLM)。它为用户提供了一个平台,用以了解这些...
评论0 喜欢0 举报
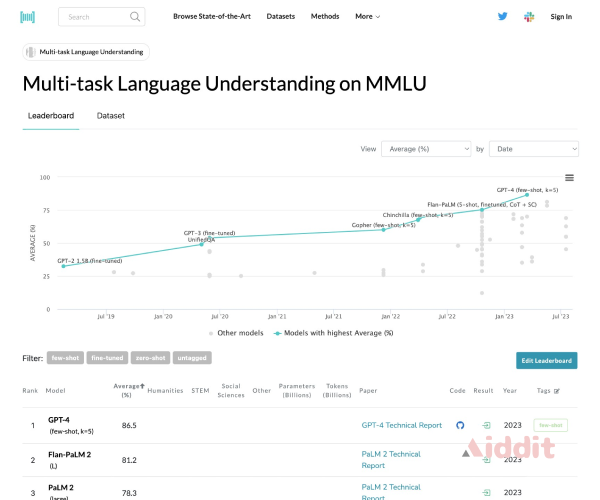
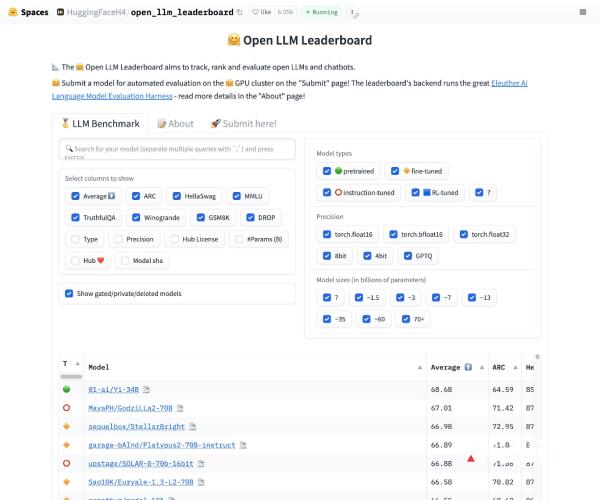
Open LLM Leaderboard
Open LLM Leaderboard 是由 Hugging Face 推出的最大规模模型和数据集社区开源模型榜单,它是基于 Eleuth...
评论1 喜欢0 举报

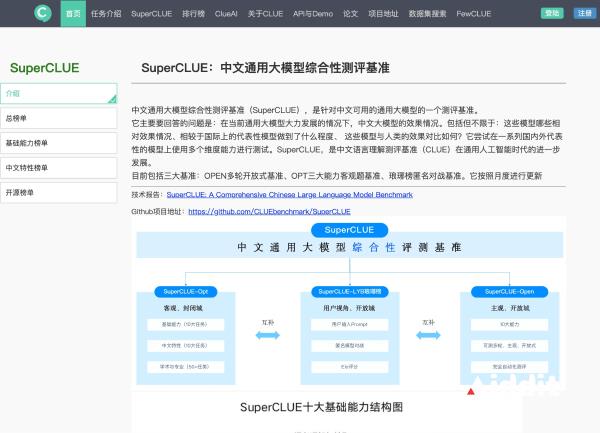
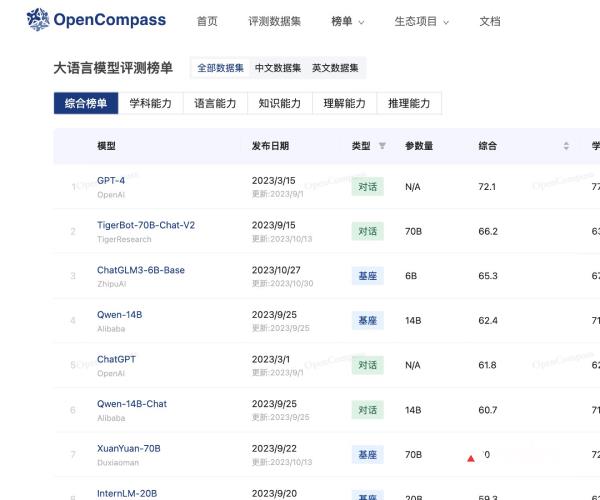
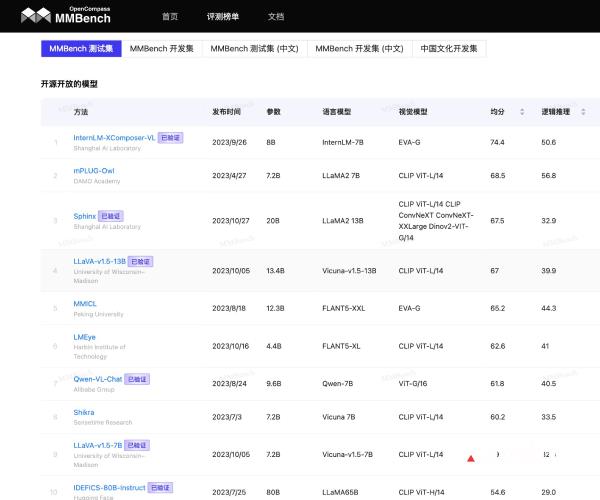
OpenCompass
OpenCompass是上海人工智能实验室(上海AI实验室)于2023年8月正式推出的一种大模型评测系统,采用完全开源且可复现的评测框架,支...
评论1 喜欢0 举报

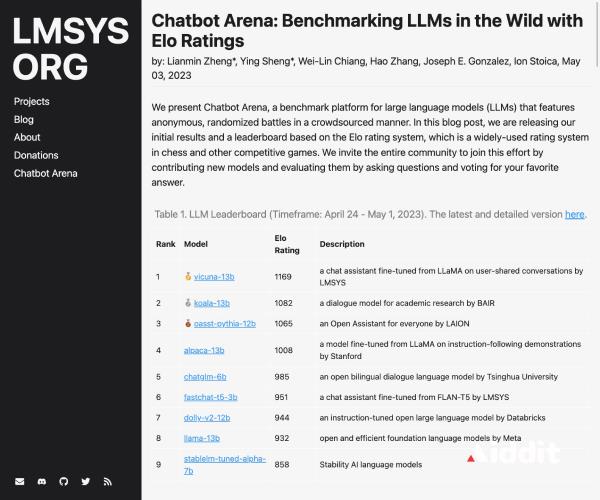
Chatbot Arena
Chatbot Arena 是一个大型的语言模型 (LLM) 基准平台,通过众包方式进行匿名的随机对战。该项目由 LMSYS Org 建立,...
评论1 喜欢0 举报