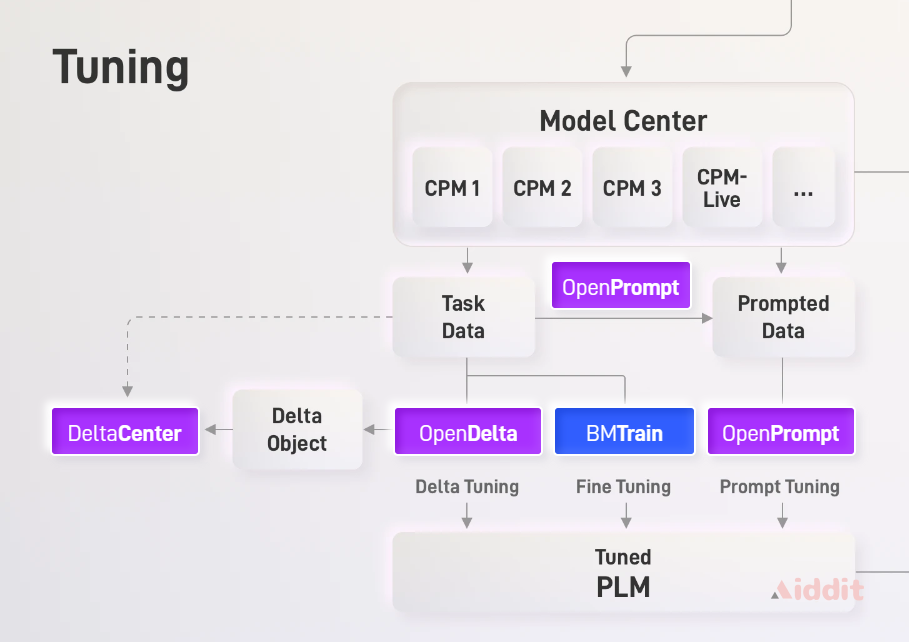
OpenBMB是Open Lab for Big Model Base的全称,旨在建立大规模预训练语言模型库及相关工具,加快百亿级以上大型模型的训练、微调和推理速度,降低使用这些大型模型的难度,与国内外开发者共同努力打造大型模型的开源社区,推动其生态系统的发展,实现这些大型模型的标准化、推广和实用化,使之广泛应用于各个领域。
OpenBMB开源社区是由清华大学自然语言处理实验室和智源研究院语言大模型加速技术创新中心合作共同发起并提供支持。 发起团队具有广泛的自然语言处理和预训练模型研究背景,近年来在模型预训练、微调提示、模型压缩等领域已在顶级国际会议上发表了多篇高水平论文。






这个工具的个性化设置很贴心,赞一个