Llama 3是Meta公司最新推出的一款开源新一代大型语言模型(LLM),拥有8B和70B两种参数规模的模型,标志着开源人工智能领域的又一次重大进步。作为Llama系列的第三代产品,Llama 3不仅继承了前一代模型的强大功能,还通过一系列创新和改进,提供了更高效、更可靠的AI解决方案,旨在应用先进的自然语言处理技术,支持广泛的应用场景,包括但不限于编程、问题解决、翻译和对话生成。
Llama 3的系列型号
目前,Llama 3系列提供了两个型号选择,分别是8B(80亿参数)和70B(700亿参数)版本。这种设计旨在满足各种应用需求,并为用户提供更灵活和多样的选择。
Llama-3-8B是一个80亿参数的8B参数模型,虽然体积较小但效率高。该模型旨在适用于需要快速推理和较少计算资源的场景,同时保持高性能标准。
Llama-3-70B是一个有700亿个参数的70B参数模型,适用于处理更加复杂的任务,具备更深入的语言理解和生成能力,非常适合需求更高性能的应用场景。
Llama 3将推出一个包含400B参数的模型,目前正在训练中。Meta公司还表示,一旦Llama 3的训练完成,他们将发布一份详尽的研究论文。
Llama 3的官网
项目官方主页链接:
https://llama.meta.com/llama3/
GitHub上的神经网络模型权重和相关代码链接:
https://github.com/meta-llama/llama3/
Hugging Face模型链接:
https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
Llama 3的改进之处
Llama 3有8B和70B两种参数规模的模型可供选择,与Llama 2相比,参数数量的增加使得模型可以更好地捕捉和学习更加复杂的语言模式。
训练数据集:Llama 3的训练数据量是Llama 2的7倍之多,包含超过15万亿个单词预测元素,其中有4倍的代码元素,这使得Llama 3在理解和生成代码方面表现更为杰出。
模型架构:Llama 3采用了更高效的分词器和分组查询注意力(GQA)技术,从而提高了模型的推理效率和处理长文本的能力。
性能改进:通过改进预训练和后训练方法,Llama 3在减少错误拒绝率、增强响应对齐性以及提高模型响应多样性等方面取得了显著进展。
安全性方面有了新的升级,如Llama Guard 2、Code Shield和CyberSec Eval 2等信任和安全工具,提高了模型的安全性和可靠性。
Llama 3支持30多种语言,预先加入高质量的非英语数据,为多语言功能奠定了基础。
逻辑思维和代码编写:Llama 3在逻辑思维、代码编写以及指令跟踪等方面展示出了显著提高的能力,使得其在处理复杂任务时更加精确和高效。
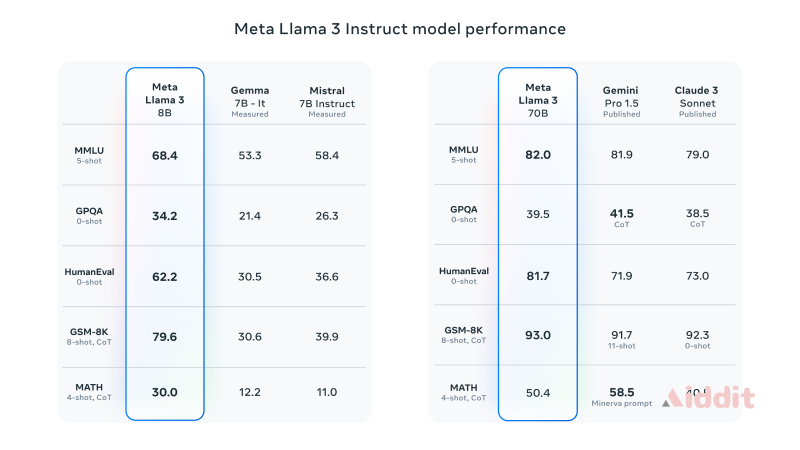
根据 Meta 官方博客的性能评估结果显示,经过指令微调的Llama 38B模型在 MMLU、GPQA、HumanEval、GSM-8K、MATH 等数据集基准测试中表现优于 Gemma 7B 和 Mistral 7B 等同规模模型;而微调后的Llama 370B在 MLLU、HumanEval、GSM-8K 等基准测试中也优于 Gemini Pro 1.5 和 Claude 3 Sonnet 等同规模模型。
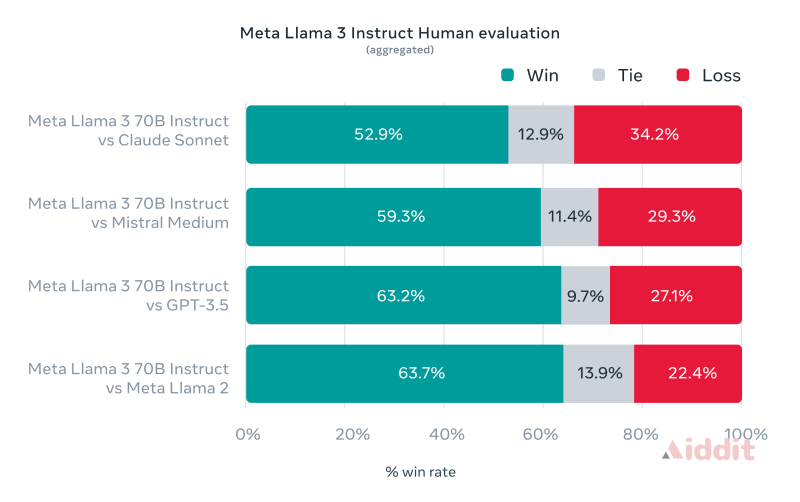
此外,Meta还开发了一套新的高质量人类评估集,包含 1800 个提示,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色/角色、开放式问答、推理、重写和总结。通过与Claude Sonnet、Mistral Medium和GPT-3.5等竞争模型的比较,人类评估者基于该评估集进行了偏好排名,结果显示Llama 3在真实世界场景中的性能非常出色,最低都有52.9%的胜出率。
Llama 3的技术结构
Llama 3的架构采用了解码器结构,这是Transformer模型的一种典型结构,用于处理自然语言生成任务。
分词器和词汇量:Llama 3采用了包含128K个标记的分词器,这有助于模型更有效地进行语言编码,从而大幅提升性能。
分组查询关注(Grouped Query Attention,GQA):为了增进推理效率,Llama 3在8B和70B模型中均采纳了GQA技术。此技术通过对注意力机制中的查询进行分组,从而降低计算负担,同时确保模型性能。
长序列处理:Llama 3可以处理长达8,192个标记的序列,采用掩码技术来保证自注意力不会跨越文档边界,这在处理长文本时至关重要。
Llama 3使用超过15TB的标记进行了预训练,在这个数据集中,不仅规模宏大,而且质量上乘,为模型提供了丰富的语言信息。
为了增强多语言功能,Llama 3的预训练数据集包含超过5% 的优质非英语数据,覆盖了30 多种语言。
数据筛选和质量控制:Llama 3的开发小组设计了一套数据筛选管道,包括启发式筛选器、NSFW(不适宜工作环境)筛选器、语义去重技术和文本分类器,以确保训练数据的优质性。
Llama 3的培训过程采用了数据并行处理、模型并行处理和流水线并行处理技术,使得模型能够在多个GPU上高效进行培训。
微调指令(Instruction Fine-Tuning):在Llama 3基础上进行了微调,进一步提高了模型在特定任务(如对话和编程)中的表现。
怎么使用Llama 3
Llama 3的开发者
Meta已在GitHub、Hugging Face、Replicate等平台上将Llama 3模型开源。开发者们可以利用torchtune等工具对Llama 3进行个性化调整和微调,以满足特定的用例和需求。有兴趣的开发者可查看官方的入门指南,并下载部署Llama 3。
Hugging Face地址:https://huggingface.co/meta-llama
Replicate地址:https://replicate.com/meta
普通用户
尤其是对技术不太了解的用户,可以按照以下步骤来体验Llama 3:
访问Meta最新推出的Meta AI聊天助手进行体验(注:Meta.AI会锁区,只有部分国家可使用)
访问Replicate提供的Chat with Llama进行体验https://llama3.replicate.dev/
使用Hugging Chat(https://huggingface.co/chat/),可手动将模型切换至Llama 3