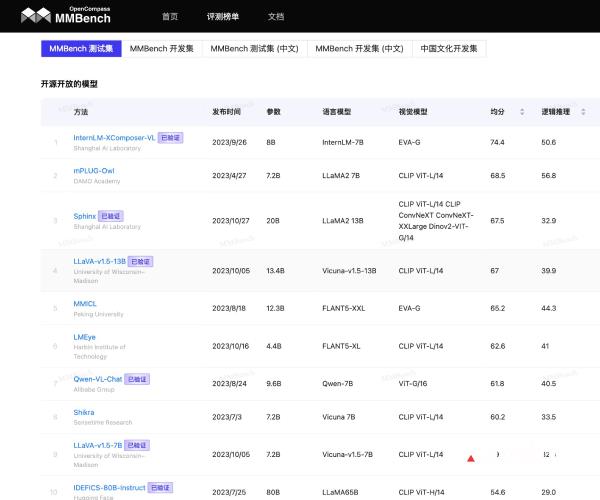
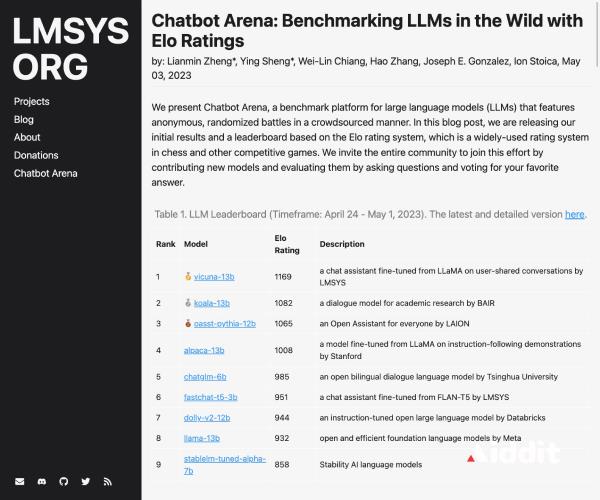
MMBench是一项多模态基准测试项目,由上海人工智能实验室、南洋理工大学、香港中文大学、新加坡国立大学和浙江大学的研究人员联合推出。该项目开发了一套全面的评估流程,从感知到认知能力进行逐级细分评估,覆盖了20种细致能力,来自互联网和权威基准数据集的约3000道单项选择题。该项目打破传统基于规则匹配的一问一答评测方式,通过循环打乱选项验证输出结果的一致性,并采用基于ChatGPT的精准匹配模型回复至选项。
MMBench的特色
对理解、关系推理等 20 个细致层面的评估维度。
MMBench是一项多模态基准测试项目,由上海人工智能实验室、南洋理工大学、香港中文大学、新加坡国立大学和浙江大学的研究人员联合推出。该项目开发了一套全面的评估流程,从感知到认知能力进行逐级细分评估,覆盖了20种细致能力,来自互联网和权威基准数据集的约3000道单项选择题。该项目打破传统基于规则匹配的一问一答评测方式,通过循环打乱选项验证输出结果的一致性,并采用基于ChatGPT的精准匹配模型回复至选项。




AI的智能推荐总能给我带来惊喜