阿里云发布了通义千问2.5版本,声称其模型性能已经全面超越了GPT-4 Turbo,成为地表上最强大的中文模型。
据报道,通盈千问2.5最新发布的规模达1100亿参数的模型,在多个基准测试中均表现出色,超越了Meta的Llama-3-70B模型,被认为是开源领域的新榜样。
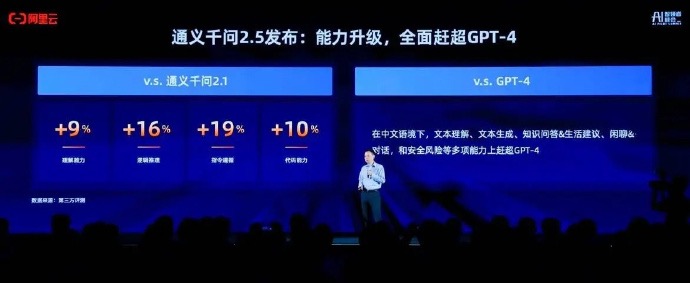
与通义千问2.1版本相比,通义千问2.5在上述四个领域的能力分别提高了9%、16%、19%和10%,特别是在中文能力方面,更是一直保持领先地位。

在权威基准OpenCompass上,通用问答2.5的得分与GPT-4 Turbo并列,打破了这一基准在国内首次有大型模型取得如此显著成绩的先例。这不仅证明了通用问答2.5在中文环境下的出色表现,也展示了阿里云在人工智能领域的创新实力。
除了通用问答数据集TQA 2.5版本之外,阿里云最近还发布了全新的开源模型Qwen1.5-110B。这个模型拥有1100亿个参数,在MMLU、TheoremQA、GPQA等基准测试中均超越了Meta的Llama-3-70B模型,并且在HuggingFace发布的开源大型模型排行榜Open LLM Leaderboard上荣登榜首,进一步巩固了通用问答开源系列在行业中的领先地位。
通用多模态模型和专属能力模型在业界展现出了强大影响力。其中,通用问题视觉理解模型Qwen-VL-Max在多项多模态标准测试中超过了Gemini Ultra和GPT-4V,目前已被多家企业采用,并为各行各业带来了实际的帮助。
另外,有一个值得一提的亮点是通义千问代码大模型CodeQwen1.5-7B。该模型在HuggingFace的Big Code代码模型榜单中排名靠前,并且是中国用户规模最大的智能编码助手通义灵码的基础。